花与堆之Large Bin Attack
Large Bin Attack
从标题就可以看出这种攻击手法和Largebin有关,分配largebin有关的chunk,需要经过fast bin、unsort bin、small bin的分配,所以在学习large bin attack之前需要搞清楚fastbin和unsortbin分配的流程。
Large Bin
large bin中一共包括63个bin,每个bin中的chunk大小不一致,而是出于一定区间范围内。此外这63个bin被分成了6组,每组bin中的chunk之间的公差一致。
Large chunk的微观结构
大于512(1024)字节的chunk称之为large chunk,large bin就是用于管理这些large chunk的
被释放进Large Bin中的chunk,除了以前经常见到的prev_size、size、fd、bk之外,还具有 fd_nextsize 和 bk_nextsize:
- fd_nextsize,bk_nextsize:只有chunk可先的时候才使用,不过用于较大的chunk(large chunk);
- fd_nextsize指向前一个与当前chunk大小不同的第一个空闲块,不包含bin的头指针;
- bk_nextsize指向后一个与当前chunk大小不同的第一个空闲块,不包含bin的头指针;
- 一般空闲的large chunk在fd的遍历顺序中,按照由大到小的顺序排列。这样可以避免在寻找合适chunk时挨个遍历。
Large Bin的插入顺序
在index相同情况下:
- 按照大小,从大到小排序(小的链接large bin块)
- 如果大小相同,按照free的时间顺序
- 多个大小相同的堆块,只有首堆块的fd_nextsize和bk_nextsize会指向其他的堆块,后面的堆块的fd_nextsize和bk_nextsize均为0
- size最大的chunk的bk_nextsize指向最小的chunk,size最小的chunk的fd_nextsize指向最大的chunk
Large Bin Attack
1 | |
程序执行流程:
- 首先定义了两个变量stack_var1和stack_var2,并且都赋值为0。
- 接下来打印出两个变量的地址stack_var1_addr和stack_var2_addr以及两个变量中的值。
- 分别申请size为0x330、0x410、0x410三个大堆块p1、p2、p3,以及三个size为0x20的小堆块。
- 然后释放掉p1和p2,并申请了一个size为0xa0的堆块,继续释放p3.接着直接修改p2的size、fd、bk、fd_nextsize、bk_nextsize。
- 申请了一个size为0xa0大小的堆块。再次打印stack_var1、stack_var2的地址和值
注:我们创建的堆块分别为三个大堆块和三个小堆块,分别为
P1,防止合并,P2,防止合并,P3,防止合并
查看stack_var1和stack_var2的地址及值
现在我们开始调试,在14行下断点,我们看一下打印出来的stack_var1和stack_var2的地址:
1 | |
可以看到stack_var1_addr为 0x7fff88da8bb8,stack_var2_addr为 0x7fff88da8bc0,两个变量中的值均为0。
查看已创建的chunk
接下来在第21行下断点,使程序完成对三个大堆块以及三个小堆块的创建:
1 | |
可以看到六个chunk已经创建完毕了,其中三个size为0x30的chunk是为了放置P1、P2、P3在释放的时候被top_chunk合并,并不是主要的执行流程。
释放P1和P2
接着断点下在24行,使程序释放p1和p2,这里需要注意的是释放顺序,先释放的是p1,后释放的是p2:
1 | |
由于刚 free() 掉了两个 chunk。现在的 unsorted bin 有两个空闲的 chunk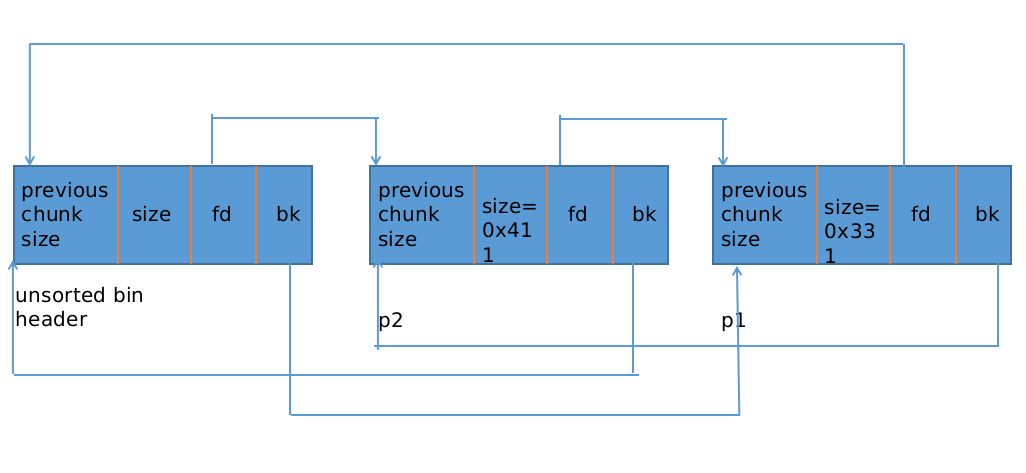
由于P1的size为0x330,P2的size为0x410,两个chunk的size均超过了fast chunk的最大值,所以在释放P1、P2的时候,两个chunk均进入unsortbin链表中。
这里还可以细分,由于P1的size小于0x3F0,所以P1最终应该归属为small bin中。P2大于0x3F0,所以P2最终应该归属为large bin中。
分割P1满足P4的请求
接下来我们将断点在第26行,使程序执行 void* p4 = malloc(0x90); 这段代码。
1 | |
void* p4 = malloc(0x90); 这段代码其实背后做了很多的事情:
- 从 unsorted bin 中拿出最后一个 chunk(p1 属于 small bin 的范围)
- 把这个 chunk 放入 small bin 中,并标记这个 small bin 有空闲的 chunk
- 再从 unsorted bin 中拿出最后一个 chunk(p2 属于 large bin 的范围)
- 把这个 chunk 放入 large bin 中,并标记这个 large bin 有空闲的 chunk
- 现在 unsorted bin 为空,从 small bin (p1)中分配一个小的 chunk 满足请求 0x90,并把剩下的 chunk(0x330 - 0xa0)放入 unsorted bin 中
也就是说,现在:
- unsorted bin 中有一个 chunk 大小是
0x330 - 0xa0 = 0x290 - large bin 某一个序列的 bin 中有一个 chunk 大小是 0x410
释放P3
接下来我们将断点端在第28行,使程序释放P3:
1 | |
由于P3的size也是大于0x3F0的,所以首先会被挂进unsorted bin中进行过渡
修改P2结构内容
接下来我们将断点下在第34行,使程序完成对P2内部结构数据的修改,这里附上修改前后的对比:
修改前:
1 | |
修改后:
1 | |
可以看到,有五处内容被修改:
- size部分由原来的0x411修改成0x3f1
- fd部分置空(不超过一个地址位长度的数据都可以)
- bk由0x7ffff7dd1f68修改成了stack_var1_addr - 0x10(0x00007fff88da8ba8)
- fd_nextsize置空(不超过一个地址位长度的数据都可以)
- bk_nextsize修改成stack_var2_addr - 0x20(0x00007fff88da8ba0)

这里需要注意的是一个chunk的bk指向的是它的后一个被释放chunk的头指针,bk_nextsize指向后一个与当前chunk大小不同的第一个空闲块的头指针:
- 也就是说当前P2的bk指向的是一个以
stack_var1_addr - 0x10为头指针的chunk,这里记做fake_chunk1,那么就意味着stack_var1_addr是作为这个fake_chunk1的fd指针。那么此时P2 --> bk --> fd就是stack_var1_addr - P2的fd_nextsize指向的是一个以
stack_var2_addr为头指针的chunk,这里记做fake_chunk2,那么就意味着stack_var2_addr是作为这个fake_chunk2的fd_nextsize指针。那么此时P2 --> bk_nextsize --> fd_nextsize就是stack_var2_addr
P3挂进Large Bin的过程
接下来我们在第36行下断点,使程序执行 malloc(0x90); 完成申请size为0xa0的chunk。这一步也很关键,与第一次分割chunk的过程一致,首先从unsorted bin中拿出最后一个chunk(P1_left size = 0x290),并放入small bin中标记该序列的small bin有空闲chunk。再从unsorted bin中拿出最后一个chunk(P3 size = 0x410),P3的size是大于0x3f0的,所以理所应当应该向large bin中挂
制定P2和P3两个large chunk的fd_nextsize和bk_nextsize,修改stack_var2的内容
从unsorted bin中拿出P3的时候,首先会判断P3应该归属的bin的类型,这里根据size判断出是large bin。由于large chunk的数据结构是带有fd_nextsize和bk_nextsize的,且large bin中已经存在了P2这个块,所以首先需要进行比较两个large chunk的大小,并根据大小情况制定两个large chunk的fd_nextsize、bk_nextsize、fd、bk的指针。在2.23的glibc中的malloc.c文件中,比较的过程如下:
1 | |
large bin中的chunk如果index相同的情况下,是按照由大到小的顺序排列的。也就是说index相同的情况下size越小的chunk,越接近large bin。这段代码就是遍历比较P3_size < P2_size的过程,我们只看while循环中的条件即可,这里的条件是当前从unsorted bin中拿出的chunk的size是否小于large bin中前一个被释放chunk的size,如果小于,则执行while循环中的流程。(重点)但由于P2的size被我们修改成了0x3f0(重点),P3的size为0x410,P3_size > P2_size,所以不执行while循环中的代码,直接进入接下来的判断
1 | |
前一个判断的是P3_size < P2_size的情况,那么接下来判断的就是P3_size == P2_size的情况,很显然也不是,所以这条if判断也不执行
1 | |
那么就只剩下一种情况了,就是比较P3_size > P2_size的情况下执行上图中的内容,else中执行的就是将P3插入large bin中并制定P2和P3两个large chunk的fd_nextsize和bk_nextsize的过程。这里我们先不着急解释代码,回顾一下前面修改P2结构内容的情况:
P2->bk->fd = stack_var1_addr(P2的fd指向的堆块的fd指向的是stack_var1的地址)P2->bk_nextsize->fd_nextsize = stack_var2_addr(P2的bk_nextsize指向的堆块的fd_nextsize指向的是stack_var2的地址)
来说一下人话:
1 | |
那么这里就像是做一个二元一次方程组一样,已知条件为:
- P2->bk_nextsize->fd_nextsize = stack_var2_addr
- P3->bk_nextsize = P2->bk_nextsize
- P3->bk_nextsize->fd_nextsize = P3
那么就可以导出结论:stack_var2的值 = P3头指针(),所以stack_var2变量中的内容就被修改成了P3的头指针。
制定P2和P3两个large chunk的fd和bk,修改stack_var1的内容
在执行完对P3和P2的fd_nextsize和bk_nextsize的制定之后,还需要对两个large chunk的fd和bk进行制定:
注:bck是P2的bk指针,victim是P3的头指针
1 | |
那么这依然还是一个二元一次方程组,已知条件为:
- P2->bk->fd = stack_var1_addr
- P2->bk->fd = P3
那么即可的出结论stack_var1的值 = P3的头指针,所以stack_var1的值在这个流程中被修改成了P3的头指针
查看修改结果
最后我们将直接运行程序至结束,再一次查看一下此时stack_var1和stack_var2中的值
1 | |
可以看到此时stack_var1和stack_var2中的值已经被修改成了P3的头指针0x137937a0
Large Bin Attack利用条件
- 可以修改一个large bin chunk的data
- 从unsorted bin中来的large bin chunk要紧跟在被构造过的chunk的后面
满足这两个条件后,我们就能让glibc向攻击者指定的任意地址,写入一个堆地址(通常是chunk的地址),而一旦我们能控制某个地址的内容,接着我们在那里伪造一个chunk,进而触发后续的漏洞利用链。
malloc.c中从unsorted bin中摘除chunk完整过程代码:
1 | |